
本节我们学习两种关键的基本算法思想:DFS(深度优先搜索)和BFS(广度优先搜索)。这两种算法和栈、队列有着千丝万缕的关系,如果前两节你认真学习掌握了,那么这一节对你来说相信不是问题。
# 深度优先搜索思想:不撞南墙不回头的“迷宫游戏”
20世纪90年代,小霸王学习机风靡全国。没有哪个小学生,不想拥有一台自己的小霸王学习机——我,也不例外;没有哪个小学生在拥有了小霸王学习机之后,会真的用它来搞学习——我,也不例外。在那个没有王者也没有吃鸡的年代里,小霸王里让我欲罢不能的除了魂斗罗、超级玛丽,还有它——迷宫游戏:

很多同学跟我说他入门算法的时候就挂在 DFS 这里,觉得太高深了,学不动。傻孩子,今天你就会知道,深度优先搜索也不过是在用编码的方式玩一场迷宫游戏。
现在把图上的小黄点想象成你自己,由于你手里没有地图、没有无人机,因此你对迷宫整体的地形一无所知。放眼望去,你眼前只有冰冷的墙壁和并不知道能不能走通的道路。如何走出一条通路?你只能尝试把每一条能走的路都走一遍——也就是所谓的“穷举法”:
- 以当前位置为起点,闷头往前走
- 在前进的过程中,难免会遇到岔路口。这个路口可能分叉出去两条、三条、四条甚至更多的道路,你只能选择其中的一条路、然后继续前进(注意,你可能会不止一次遇到岔路口;每遇到一个新的岔路口,你都需要做一次选择)。
- 你选择的这条路未必是一条通路。如果你走到最后发现此路不通,那么你就要退回到离你最近的那个分叉路口,然后尝试看其它的岔路能不能走通。如果当前的岔路口分叉出去的所有道路都走不通,那么就需要退回到当前岔路口的上一个岔路口,进一步去寻找新的路径。
按照这个思路走下去,只要迷宫是有出口的,你就一定能找到这个出口。在这个过程里,我们贯彻了“不撞南墙不回头”的原则:只要没有碰壁,就决不选择其它的道路,而是坚持向当前道路的深处挖掘——像这样将“深度”作为前进的第一要素的搜索方法,就是所谓的“深度优先搜索”。
深度优先搜索的核心思想,是试图穷举所有的完整路径。
# 深度优先搜索的本质——栈结构
那么如何使用编码来实现深度优先搜索呢?我们继续讨论迷宫问题,这里我给大家一个抽象过后的简单迷宫结构:
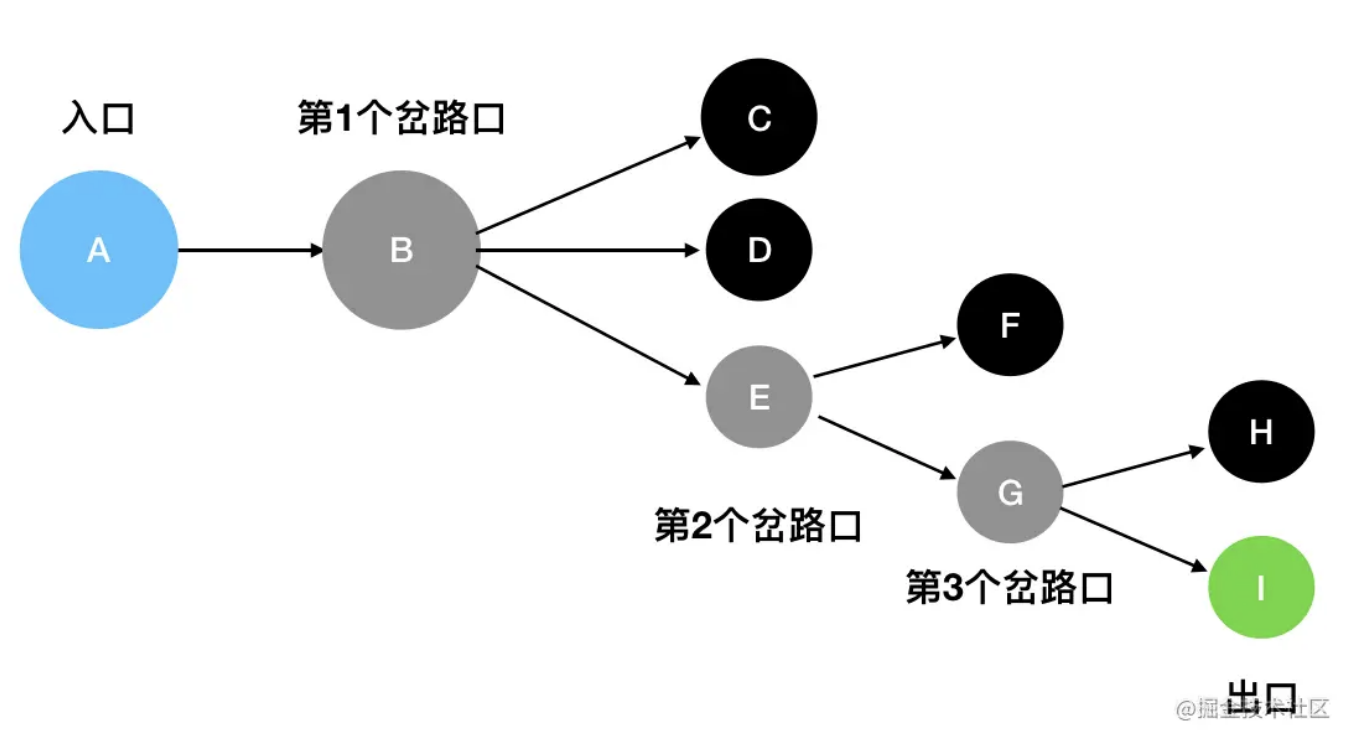
图中蓝色的是入口,灰色的是岔路口,黑色的是死胡同,绿色的是出口。
基于眼前的这个迷宫结构,我们来一步一步模拟一下深度优先搜索的具体过程:
- 从 A 出发,沿着唯一的一条道路往下走,遇到了第1个岔路口B。眼前有三个选择:C、D、E。这里我按照从上到下的顺序来走(你也可以按照其它顺序),先走C。
- 发现 C是死胡同,后退到最近的岔路口 B,尝试往D方向走。
- 发现D 是死胡同,,后退到最近的岔路口 B,尝试往E方向走。
- E 是一个岔路口,眼前有两个选择:F 和 G。按照从上到下的顺序来走,先走F。
- 发现F 是死胡同,后退到最近的岔路口 E,尝试往G方向走。
- G 是一个岔路口,眼前有两个选择:H 和 I。按照从上到下的顺序来走,先走H。
- 发现 H 是死胡同,后退到最近的岔路口 G,尝试往I方向走。
- I 就是出口,成功走出迷宫。
大家观察一下这个过程,会不会觉得这些前进、后退的操作,其实和栈结构的入栈、出栈过程非常相似呢?
现在我们把迷宫中的每一个坐标看做是栈里的一个元素,用栈来模拟这个过程:
- 从 A 出发(A入栈),经过了B(B入栈),接下来面临 C、D、E三条路。这里按照从上到下的顺序来走(你也可以选择其它顺序),先走C(C入栈)。
- 发现 C是死胡同,后退到最近的岔路口 B(C出栈),尝试往D方向走(D入栈)。
- E 是一个岔路口,眼前有两个选择:F 和 G。按照从上到下的顺序来走,先走F(F入栈)。
- 发现F 是死胡同,后退到最近的岔路口 E(F出栈),尝试往G方向走(G入栈)。
- G 是一个岔路口,眼前有两个选择:H 和 I。按照从上到下的顺序来走,先走H(H入栈)。
- 发现 H 是死胡同,后退到最近的岔路口 G(H出栈),尝试往I方向走(I入栈)。
- I 就是出口,成功走出迷宫。
此时栈里面的内容就是A、B、E、G、I,因此 A->B->E->G->I 就是走出迷宫的路径。通过深度优先搜索,我们不仅可以定位到迷宫的出口,还可以记录下相关的路径信息。
现在大家知道了深度优先搜索的过程可以转化为一系列的入栈、出栈操作。那么深度优先搜索在编码上一般会如何实现呢?这里,就需要大家回忆一下第 5 节的内容了——DFS 中,我们往往使用递归来模拟入栈、出栈的逻辑。
# DFS 与二叉树的遍历
现在我们站在深度优先搜索的角度,重新理解一下二叉树的先序遍历过程:
从 A 结点出发,访问左侧的子结点;如果左子树同样存在左侧子结点,就头也不回地继续访问下去。一直到左侧子结点为空时,才退回到距离最近的父结点、再尝试 去访问父结点的右侧子结点——这个过程,和走迷宫是何其相似!事实上,在二叉树中,结点就好比是迷宫里的坐标,图中的每个结点在作为父结点时无疑是岔路口,而空结点就是死胡同。我们回顾一下二叉树先序遍历的编码实现:
// 所有遍历函数的入参都是树的根结点对象
function preorder(root) {
// 递归边界,root 为空
if(!root) {
return
}
// 输出当前遍历的结点值
console.log('当前遍历的结点值是:', root.val)
// 递归遍历左子树
preorder(root.left)
// 递归遍历右子树
preorder(root.right)
}
在这个递归函数中,递归式用来先后遍历左子树、右子树(分别探索不同的道路),递归边界在识别到结点为空时会直接返回(撞到了南墙)。因此,我们可以认为,递归式就是我们选择道路的过程,而递归边界就是死胡同。二叉树的先序遍历正是深度优先搜索思想的递归实现。可以说深度优先搜索过程就类似于树的先序遍历、是树的先序遍历的推广。
这时候,可能有同学会有疑问:在二叉树遍历的递归实现里,完全没有栈的影子——这东西似乎和栈没有什么直接联系啊,为啥咱们还说深度优先搜索的本质是栈呢?